
Authors:
(1) Guillaume Staerman, INRIA, CEA, Univ. Paris-Saclay, France;
(2) Marta Campi, CERIAH, Institut de l’Audition, Institut Pasteur, France;
(3) Gareth W. Peters, Department of Statistics & Applied Probability, University of California Santa Barbara, USA.
Table of Links
2.1. Functional Isolation Forest
3. Signature Isolation Forest Method
4.1. Parameters Sensitivity Analysis
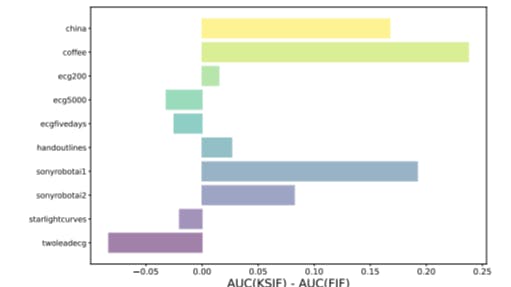
4.2. Advantages of (K-)SIF over FIF
4.3. Real-data Anomaly Detection Benchmark
5. Discussion & Conclusion, Impact Statements, and References
Appendix
A. Additional Information About the Signature
C. Additional Numerical Experiments
5. Discussion & Conclusion
This work presents two novel anomaly detection algorithms, K-SIF and SIF, rooted in the isolation forest structure and the signature approach from rough path theory. Our contributions extend Functional Isolation Forest in two vital dimensions: incorporating non-linear properties in data for improved adaptability to challenging datasets and introducing an entirely data-driven technique free from predefined dictionaries. Such flexibility accommodates diverse data
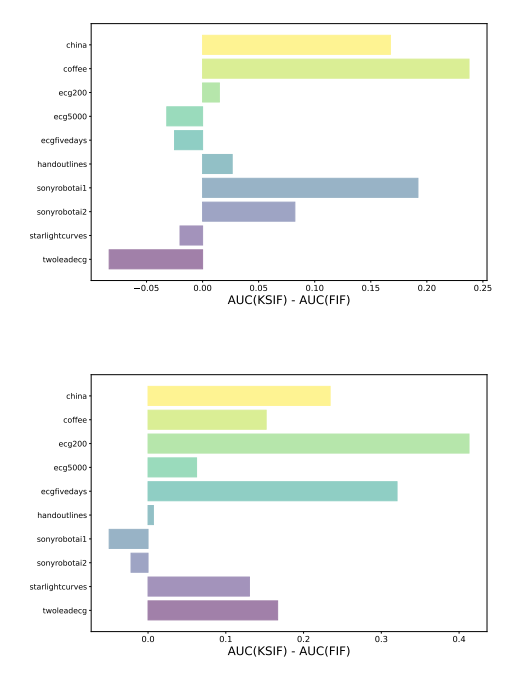
patterns and reduces the risk of overlooking certain types of anomalies. In this way, more complex real data pattern scenarios can be analysed, where non-linearity is highly present and, further, the unsupervised settings lacking labels highly affect the AD task. We demonstrate the advantages of utilizing K-SIF over FIF through a comprehensive parameter analysis, with consistent outperformance on real-world datasets. Notably, SIF achieves state-of-the-art performance while maintaining simplicity and computational efficiency, underscoring its effectiveness in functional anomaly detection. This work offers valuable advancements in anomaly detection methodologies, providing robust solutions for complex and diverse datasets.
Impact Statements
This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here.
References
Breunig, M., Kriegel, H.-P., Ng, R., and Sander, J. (2000). LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, volume 29, pages 93–104. ACM.
Chandola, V., Banerjee, A., and Kumar, V. (2009). Anomaly detection: A survey. ACM Computing Surveys (CSUR), 41(3):15:1–15:58.
Chen, K.-T. (1958). Integration of paths–a faithful representation of paths by noncommutative formal power series. Transactions of the American Mathematical Society, 89(2):395–407.
Chen, Y., Keogh, E., Hu, B., Begum, N., Bagnall, A., Mueen, A., and Batista, G. (2015). The UCR time series classification archive.
Chevyrev, I. and Kormilitzin, A. (2016). A primer on the signature method in machine learning. arXiv preprint arXiv:1603.03788.
Chevyrev, I. and Oberhauser, H. (2022). Signature moments to characterize laws of stochastic processes. The Journal of Machine Learning Research, 23(1):7928–7969.
Claeskens, G., Hubert, M., Slaets, L., and Vakili, K. (2014). Multivariate functional halfspace depth. Journal of the American Statistical Association, 109(505):411–423.
Clemencon, S., Mozharovskyi, P., and Staerman, G. (2023). Affine invariant integrated rank-weighted statistical depth: properties and finite sample analysis. Electronic Journal of Statistics, 17(2):3854–3892.
Colombo, P., Dadalto, E., Staerman, G., Noiry, N., and Piantanida, P. (2022). Beyond mahalanobis distance for textual ood detection. Advances in Neural Information Processing Systems, 35:17744–17759.
Colombo, P., Picot, M., Noiry, N., Staerman, G., and Piantanida, P. (2023). Toward stronger textual attack detectors. arXiv preprint arXiv:2310.14001.
Cuevas, A., Febrero, M., and Fraiman, R. (2007). Robust estimation and classification for functional data via projection-based depth notions. Computational Statistics, 22(3):481–496.
Dadalto, E., Colombo, P., Staerman, G., Noiry, N., and Piantanida, P. (2023). A functional data perspective and baseline on multi-layer out-of-distribution detection. arXiv preprint arXiv:2306.03522.
Darrin, M., Staerman, G., Gomes, E. D. C., Cheung, J. C., Piantanida, P., and Colombo, P. (2023). Unsupervised layer-wise score aggregation for textual ood detection. arXiv preprint arXiv:2302.09852.
Dauxois, J., Pousse, A., and Romain, Y. (1982). Asymptotic theory for the principal component analysis of a vector random function: some applications to statistical inference. Journal of multivariate analysis, 12(1):136–154.
Fermanian, A. (2021). Embedding and learning with signatures. Computational Statistics & Data Analysis, 157:107148.
Ferraty, F. (2006). Nonparametric functional data analysis. Springer.
Fraiman, R. and Muniz, G. (2001). Trimmed means for functional data. Test, 10:419–440.
Friz, P. K. and Victoir, N. B. (2010). Multidimensional stochastic processes as rough paths: theory and applications, volume 120. Cambridge University Press.
Gijbels, I. and Nagy, S. (2017). On a General Definition of Depth for Functional Data. Statistical Science, 32(4):630 – 639.
Himmi, A., Staerman, G., Picot, M., Colombo, P., and Guerreiro, N. M. (2024). Enhanced hallucination detection in neural machine translation through simple detector aggregation. arXiv preprint arXiv:2402.13331.
Hubert, M., Rousseeuw, P. J., and Segaert, P. (2015). Multivariate functional outlier detection. Statistical Methods & Applications, 24(2):177–202.
Kiraly, F. J. and Oberhauser, H. (2019). Kernels for se- ´ quentially ordered data. Journal of Machine Learning Research, 20.
Koshevoy, G. and Mosler, K. (1997). Zonoid trimming for multivariate distributions. The Annals of Statistics, 25(5):1998–2017.
Lee, D. and Oberhauser, H. (2023). The signature kernel. arXiv preprint arXiv:2305.04625.
Liu, F. T., Ting, K. M., and Zhou, Z.-H. (2008). Isolation forest. In 2008 eighth ieee international conference on data mining, pages 413–422. IEEE.
Liu, R. Y. (1988). On a notion of simplicial depth. Proceedings of the National Academy of Sciences, 85(6):1732– 1734.
Liu, R. Y. and Singh, K. (1993). A quality index based on data depth and multivariate rank tests. Journal of the American Statistical Association, 88(421):252–260.
Lopez-Pintado, S. and Romo, J. (2009). On the concept ´ of depth for functional data. Journal of the American statistical Association, pages 718–734.
Lopez-Pintado, S. and Romo, J. (2011). A half-region depth ´ for functional data. Computational Statistics & Data Analysis, 55(4):1679–1695.
Lyons, T. and McLeod, A. D. (2022). Signature methods in machine learning. arXiv preprint arXiv:2206.14674.
Lyons, T. J., Caruana, M., and Levy, T. (2007). ´ Differential equations driven by rough paths. Springer.
Morrill, J., Kormilitzin, A., Nevado-Holgado, A., Swaminathan, S., Howison, S., and Lyons, T. (2019). The signature-based model for early detection of sepsis from electronic health records in the intensive care unit. In 2019 Computing in Cardiology (CinC), pages Page–1. IEEE.
Nieto-Reyes, A. and Battey, H. (2016). A Topologically Valid Definition of Depth for Functional Data. Statistical Science, 31(1):61 – 79.
Picot, M., Granese, F., Staerman, G., Romanelli, M., Messina, F., Piantanida, P., and Colombo, P. (2022). A halfspace-mass depth-based method for adversarial attack detection. Transactions on Machine Learning Research.
Polonik, W. (1997). Minimum volume sets and generalized quantile processes. Stochastic processes and their applications, 69(1):1–24.
Ramsay, J. O. and Silverman, B. W. (2005). Fitting differential equations to functional data: Principal differential analysis. Springer.
Reutenauer, C. (2003). Free lie algebras. In Handbook of algebra, volume 3, pages 887–903. Elsevier.
Rossi, F. and Villa, N. (2006). Support vector machine for functional data classification. Neurocomputing, 69(7- 9):730–742.
Rousseeuw, P. J. and Driessen, K. V. (1999). A fast algorithm for the minimum covariance determinant estimator. Technometrics, 41(3):212–223.
Rousseeuw, P. J. and Hubert, M. (1999). Regression depth. Journal of the American Statistical Association, 94(446):388–402.
Salvi, C., Cass, T., Foster, J., Lyons, T., and Yang, W. (2021). The signature kernel is the solution of a goursat pde. SIAM Journal on Mathematics of Data Science, 3(3):873– 899.
Scholkopf, B., Platt, J., Shawe-Taylor, J., Smola, A., and ¨ Williamson, R. (2001). Estimating the support of a high-dimensional distribution. Neural Computation, 13(7):1443–1471.
Scholkopf, B., Platt, J. C., Shawe-Taylor, J., Smola, A. J., ¨ and Williamson, R. C. (2001). Estimating the support of a high-dimensional distribution. Neural computation, 13(7):1443–1471.
Shang, H. L. (2014). A survey of functional principal component analysis. AStA Advances in Statistical Analysis, 98:121–142.
Staerman, G. (2022). Functional anomaly detection and robust estimation. PhD thesis, Institut polytechnique de Paris.
Staerman, G., Adjakossa, E., Mozharovskyi, P., Hofer, V., Sen Gupta, J., and Clemenc¸on, S. (2023). Functional anomaly detection: a benchmark study. International Journal of Data Science and Analytics, 16(1):101–117.
Staerman, G., Laforgue, P., Mozharovskyi, P., and d’Alche´ Buc, F. (2021a). When ot meets mom: Robust estimation of wasserstein distance. In International Conference on Artificial Intelligence and Statistics, pages 136–144. PMLR.
Staerman, G., Mozharovskyi, P., Clemen, S., et al. (2020). ´ The area of the convex hull of sampled curves: a robust functional statistical depth measure. In International Conference on Artificial Intelligence and Statistics, pages 570–579. PMLR.
Staerman, G., Mozharovskyi, P., Clemen ´ c¸on, S., and d’Alche Buc, F. (2019). Functional isolation forest. In ´ Asian Conference on Machine Learning, pages 332–347. PMLR.
Staerman, G., Mozharovskyi, P., Colombo, P., Clemen ´ c¸on, S., and d’Alche Buc, F. (2021b). A pseudo-metric be- ´ tween probability distributions based on depth-trimmed regions. arXiv preprint arXiv:2103.12711.
Tukey, J. (1975). Mathematics and picturing data. pages 523–531. Canadian Math. Congress.
Vardi, Y. and Zhang, C.-H. (2000). The multivariate l 1- median and associated data depth. Proceedings of the National Academy of Sciences, 97(4):1423–1426.
Wang, J.-L., Chiou, J.-M., and Muller, H.-G. (2016). Func- ¨ tional data analysis. Annual Review of Statistics and its application, 3:257–295.
Wilson-Nunn, D., Lyons, T., Papavasiliou, A., and Ni, H. (2018). A path signature approach to online arabic handwriting recognition. In 2018 IEEE 2nd International Workshop on Arabic and Derived Script Analysis and Recognition (ASAR), pages 135–139. IEEE.
Yang, W., Jin, L., and Liu, M. (2016a). Deepwriterid: An end-to-end online text-independent writer identification system. IEEE Intelligent Systems, 31(2):45–53.
Yang, W., Jin, L., Tao, D., Xie, Z., and Feng, Z. (2016b). Dropsample: A new training method to enhance deep convolutional neural networks for large-scale unconstrained handwritten chinese character recognition. Pattern Recognition, 58:190–203.
Zuo, B. and Serfling, R. (2000). General notions of statistical depth function. The Annals of Statistics, 28(2):461– 482.
This paper is available on arxiv under CC BY 4.0 DEED license.