

Authors:
(1) Wanru Zhao, University of Cambridge, Shanghai AI Laboratory with Equal contribution;
(2) Yaxin Du, Shanghai Jiao Tong University with Equal contribution;
(3) Nicholas D. Lane, University of Cambridge and Flower Labs;
(4) Siheng Chen, Shanghai AI Laboratory and Shanghai Jiao Tong University;
(5) Yanfeng Wang, Shanghai AI Laboratory and Shanghai Jiao Tong University.
Table of Links
- Abstract and Introduction
- Motivation and Setup: How low-quality data affects the performance of Collaborative Training
- Proposed Workflow for Data Quality Control
- Experiments
- Conclusion and Future Work, and References
- A. Related Work
- B. Heterogeneity Settings
- C. Experimental Details
- D. Ablation study of Unified Scoring with Anchor Data
- E. Examples for low-and high- quality Data
B HETEROGENEITY SETTINGS
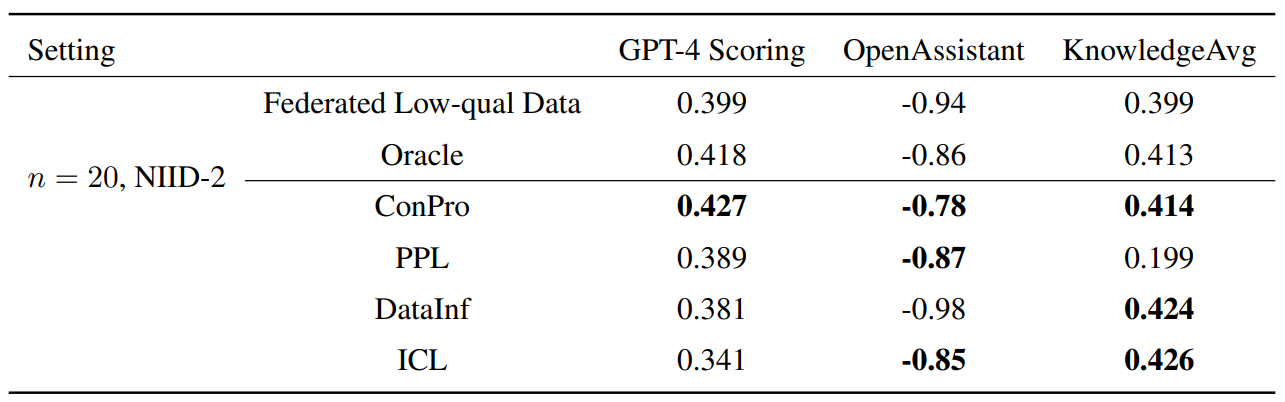
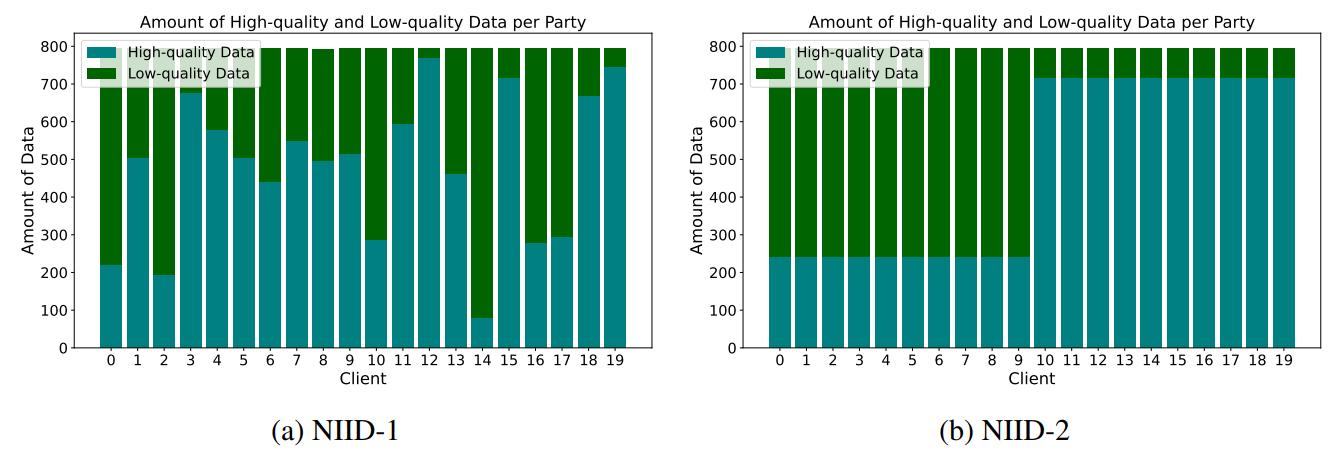
To model real-world scenario, we designed two heterogeneous settings: NIID-1 and NIID-2. NIID-1 replicates a typical scenario in federated learning classification tasks (Yurochkin et al., 2019; Wang et al., 2020a;b; Li et al., 2021; Shi et al., 2022), where the distribution of low-quality data among clients follows a Dirichlet distribution with parameter β = 1, while ensuring that the volume of data processed by each client remains equal. In contrast, NIID-2 addresses a skewed classification task scenario within FL (McMahan et al., 2017; Li et al., 2020), assigning 70% of low-quality data to half of the clients and 90% to the other half, yet maintaining an equal size of training data across all clients. The distributions for these settings are illustrated in Figure 3. Table2 shows the low-quality data traing and data quality control federated NIID-2 setting.
This paper is available on arxiv under CC BY 4.0 DEED license.