

Authors:
(1) Wanru Zhao, University of Cambridge, Shanghai AI Laboratory with Equal contribution;
(2) Yaxin Du, Shanghai Jiao Tong University with Equal contribution;
(3) Nicholas D. Lane, University of Cambridge and Flower Labs;
(4) Siheng Chen, Shanghai AI Laboratory and Shanghai Jiao Tong University;
(5) Yanfeng Wang, Shanghai AI Laboratory and Shanghai Jiao Tong University.
Table of Links
- Abstract and Introduction
- Motivation and Setup: How low-quality data affects the performance of Collaborative Training
- Proposed Workflow for Data Quality Control
- Experiments
- Conclusion and Future Work, and References
- A. Related Work
- B. Heterogeneity Settings
- C. Experimental Details
- D. Ablation study of Unified Scoring with Anchor Data
- E. Examples for low-and high- quality Data
3 PROPOSED WORKFLOW FOR DATA QUALITY CONTROL
3.1 OVERVIEW

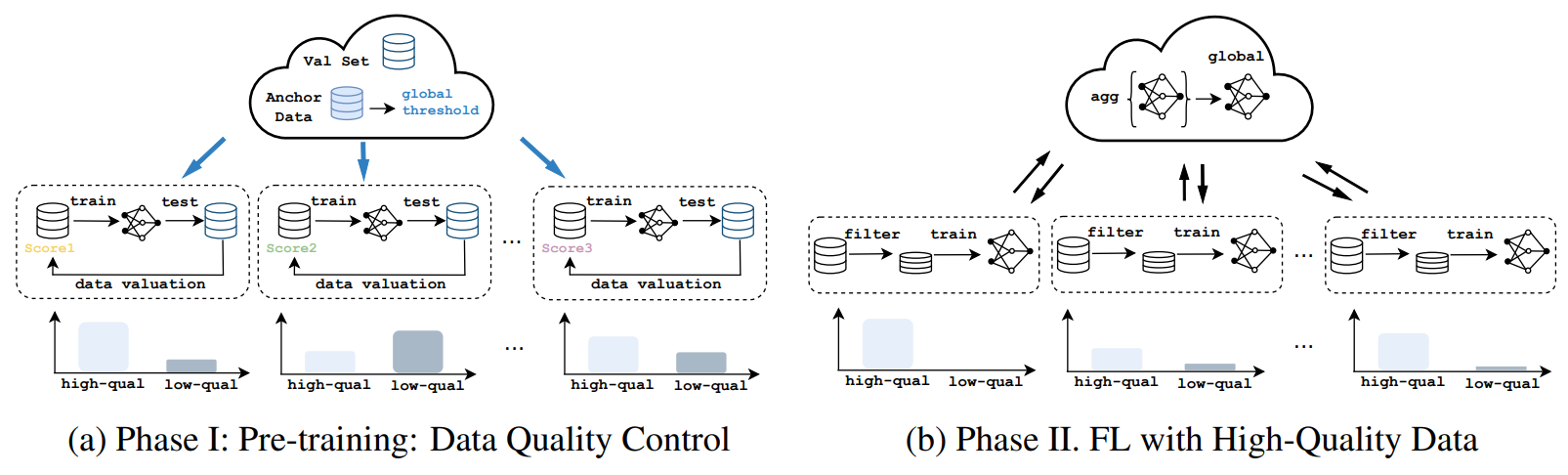
3.2 LOCAL DATA SCORING AND QUALITY CONTROL

3.3 GLOBAL STANDARD WITH ANCHOR DATA SCORING
On the server, we select only a few amount of data (10 samples in our paper) as our anchor data and use the aforementioned scoring method to calculate the average score of these 10 data points as the global threshold. This establishes a unified standard for division between low- and high-quality data for heterogeneous clients, allowing for the further filtering of local data.
This paper is available on arxiv under CC BY 4.0 DEED license.